[내목소리 TTS 만들기] 04. HiFi-GAN 학습
#colaboratory #tts #내목소리 #hifigan #hifi #학습 #만들기
[내목소리 TTS 만들기] 04. HiFi-GAN 학습
아래 링크를 기반으로 진행하지만, 그대로 하면 문제가 생기므로 잘 보고 진행하셔야 합니다.
https://sce-tts.github.io/#/v2/train
train hifigan ipynb를 구글 드라이브에서 엽니다.
2. 내 드라이브에 저장합니다.
3. 코드를 추가하여 pip, python 3.6 버전을 설치합니다.
* 파일 설명에 써진대로 '모두 실행' 하시면 안됩니다.

!apt-get install python3.6
!update-alternatives --install /usr/bin/python python /usr/bin/python3.6 1
!update-alternatives --set python /usr/bin/python3.6
!apt-get install python3.6-dev -y
!apt-get install python3.6-distutils -y
!curl https://bootstrap.pypa.io/pip/3.6/get-pip.py | /usr/bin/python3.6

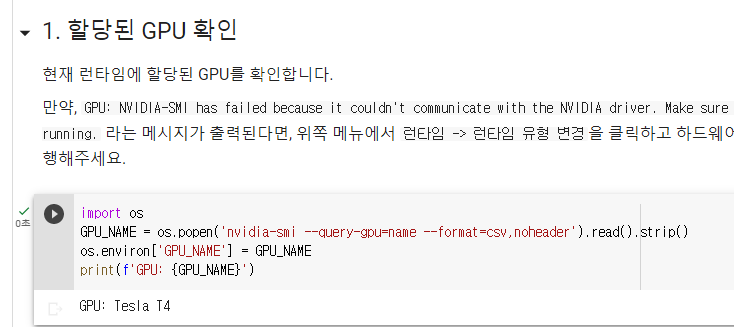
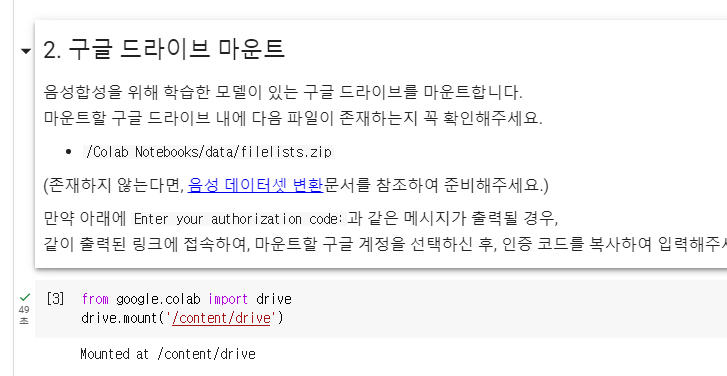
4. GPU 확인 및 구글 드라이브 마운트
5. 필수 라이브러리 및 함수 불러오기
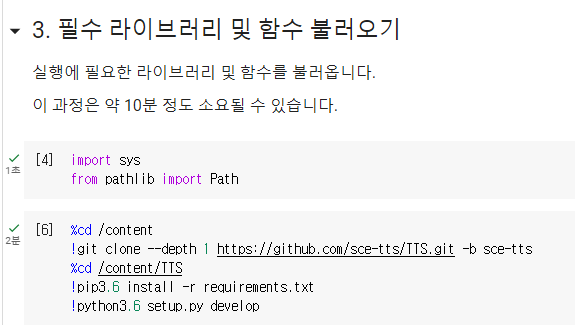
기존 스크립트는 디펜던시를 설치 하는 단계가 없어 추가했습니다.
%cd /content
!git clone --depth 1 https://github.com/sce-tts/TTS.git -b sce-tts
%cd /content/TTS
!pip3.6 install -r requirements.txt
!python3.6 setup.py develop

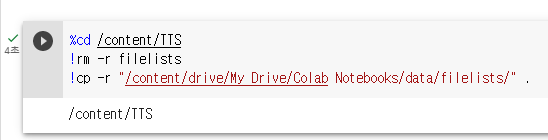
6. 데이터셋 불러오기
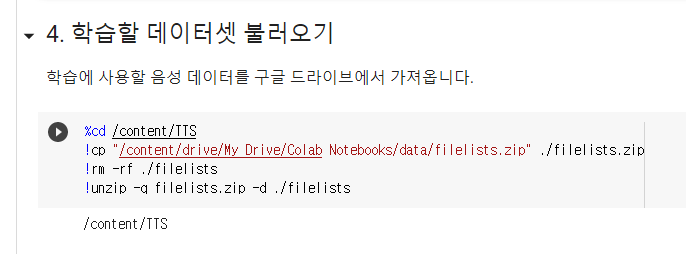
저는 zip이 아니라 폴더 형태로 저장되어 있어 폴더를 그냥 가져왔습니다.
7. 사전 학습 데이터 불러오기
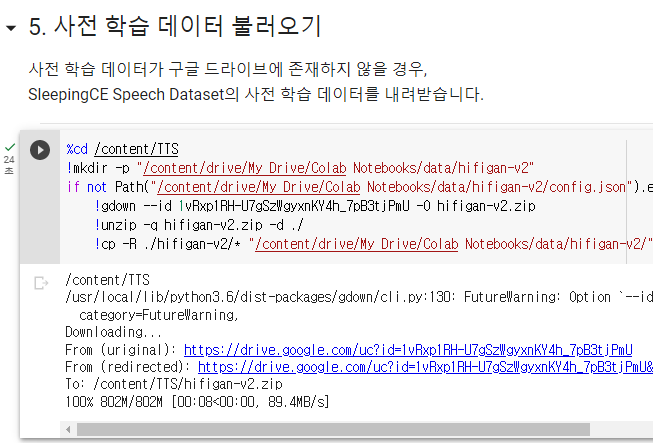
그 다음 두번째 쉘 진행때는 파이썬 버전을 수정해야 합니다.

잘 실행됐다면 아래는 넘어가세요
---------
여기서 'v cannot be empty' 라는 에러가 발생될 수 있습니다.
Traceback (most recent call last):
File "TTS/bin/compute_statistics.py", line 96, in <module>
main()
File "TTS/bin/compute_statistics.py", line 55, in main
linear = ap.spectrogram(wav)
File "/content/TTS/TTS/utils/audio.py", line 275, in spectrogram
D = self._stft(self.apply_preemphasis(y))
File "/content/TTS/TTS/utils/audio.py", line 259, in apply_preemphasis
return scipy.signal.lfilter([1, -self.preemphasis], [1], x)
File "/usr/local/lib/python3.6/dist-packages/scipy/signal/signaltools.py", line 1890, in lfilter
out_full = np.apply_along_axis(lambda y: np.convolve(b, y), axis, x)
File "<__array_function__ internals>", line 6, in apply_along_axis
File "/usr/local/lib/python3.6/dist-packages/numpy/lib/shape_base.py", line 379, in apply_along_axis
res = asanyarray(func1d(inarr_view[ind0], *args, **kwargs))
File "/usr/local/lib/python3.6/dist-packages/scipy/signal/signaltools.py", line 1890, in <lambda>
out_full = np.apply_along_axis(lambda y: np.convolve(b, y), axis, x)
File "<__array_function__ internals>", line 6, in convolve
File "/usr/local/lib/python3.6/dist-packages/numpy/core/numeric.py", line 815, in convolve
raise ValueError('v cannot be empty')
ValueError: v cannot be empty
그러면 TTS/bin/compute_statistics.py 에서 print를 추가해 어느 파일에서 문제가 됐는지 확인하고 삭제할 겁니다.
파일은 왼쪽의 파일탐색기에서 쉽게 찾을 수 있습니다.
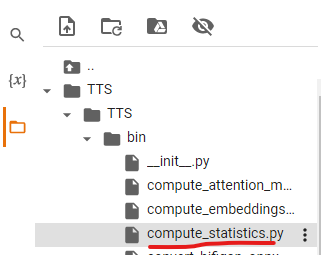
더블클릭하면 편집기가 열립니다.
여기서 55번 줄에 item을 출력하는 print 함수를 추가합니다.

저장하고 다시 진행하면 어떤 파일에서 문제가 됐는지 확인할 수 있습니다.
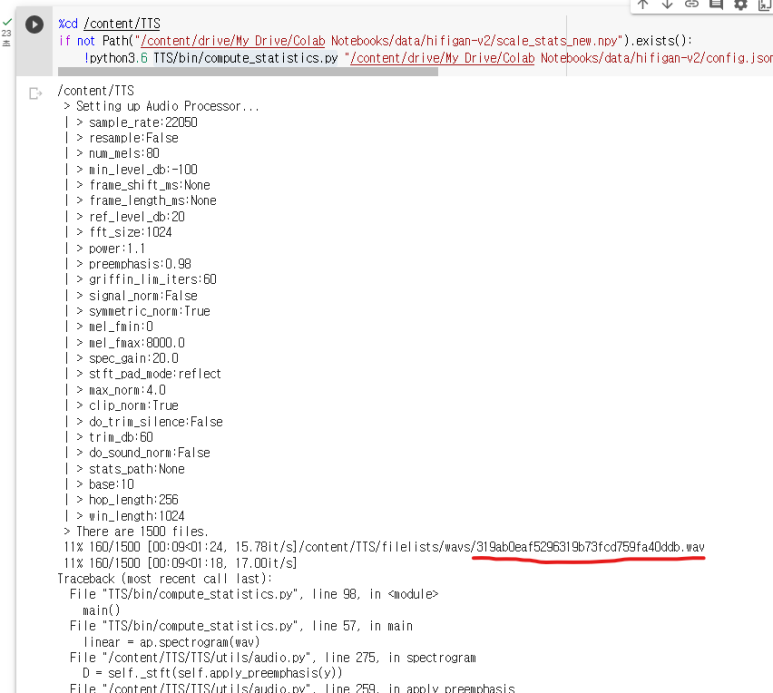
찾은 파일은 해당 위치로 찾아가서 삭제하시면 됩니다.
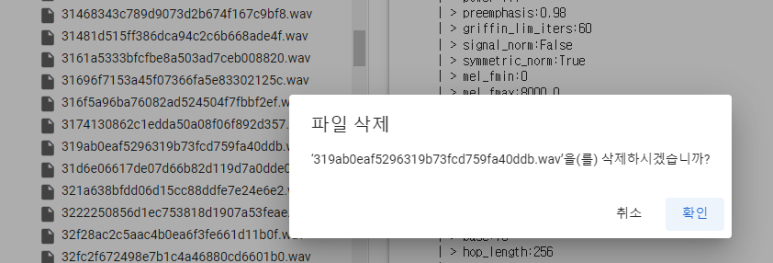
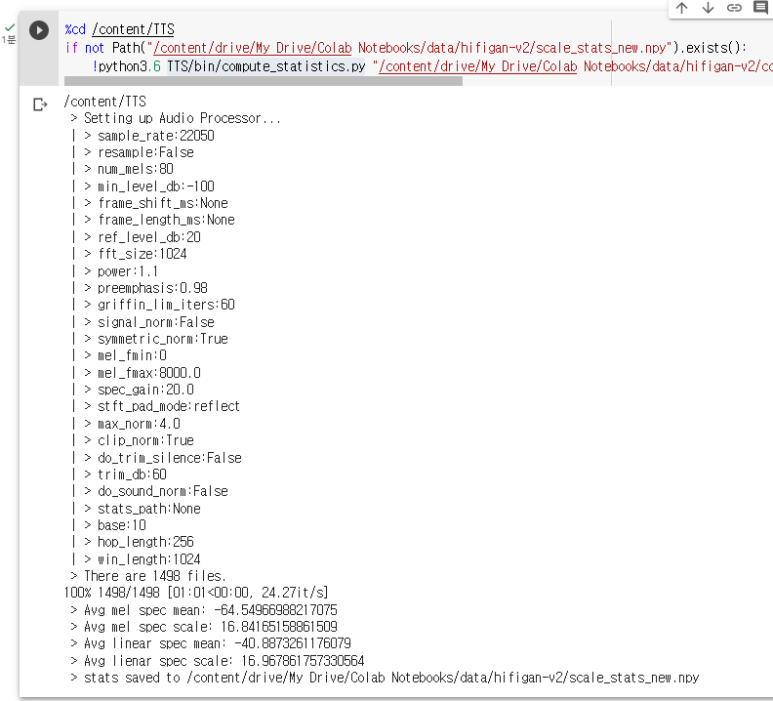
완료된 모습
8. 텐서보드 실행
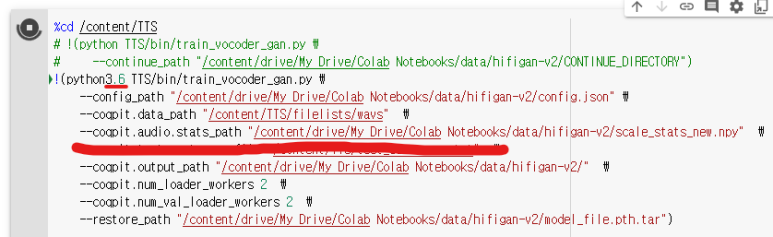
9. HiFi-GAN 학습
시작 전에 ipykernel을 먼저 설치해주세요
!pip3.6 install ipykernel
python3.6은 꼭 바꾸셔야 합니다.
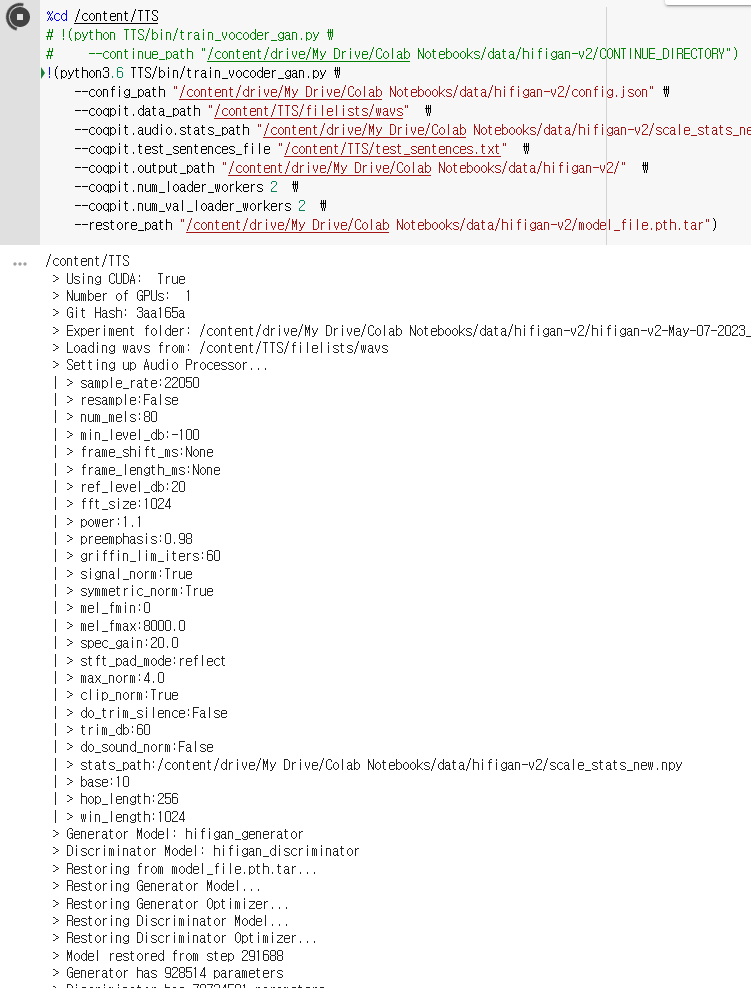
그럼 무난히 진행됩니다.
나머지는 시간 문제이기 때문에...
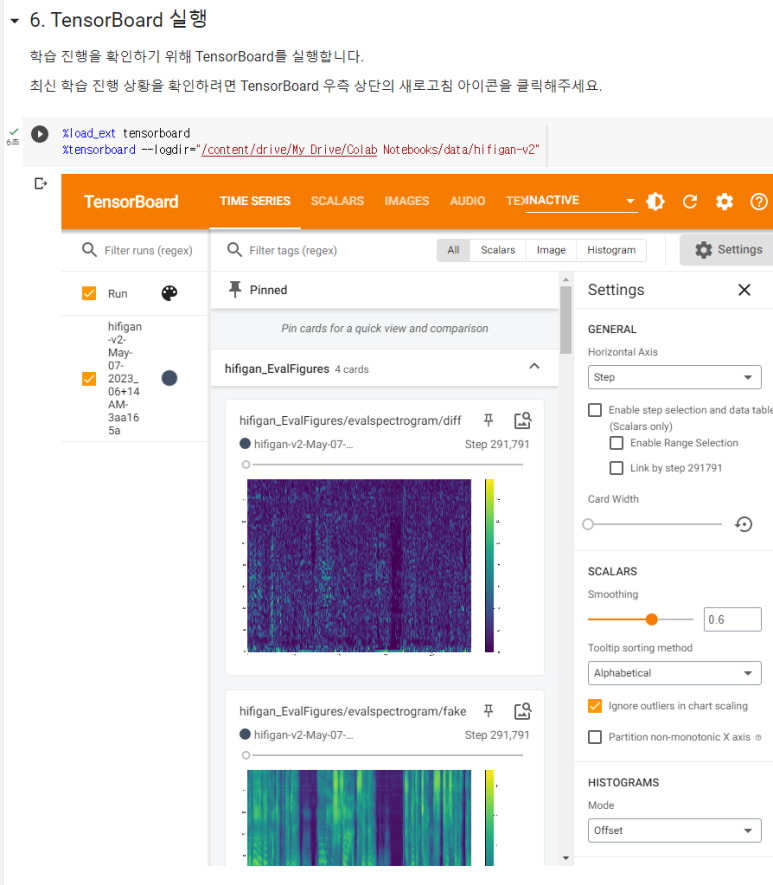
텐서보드 새로고침하시고 모니터링 하면 됩니다.
[출처] [내목소리 TTS 만들기] 04. HiFi-GAN 학습|작성자 Secondpage
네이버 게시글 옮기는 중...작성일: 2023. 5. 7. 15:19